一 .简单使用Tesseract文字识别
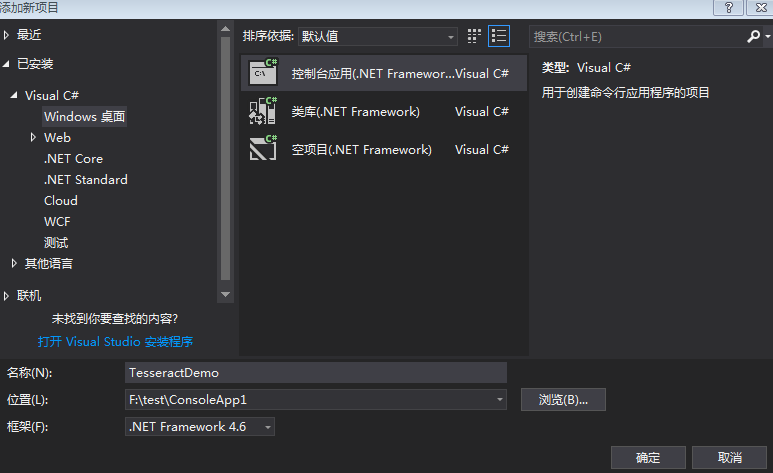
1.创建项目
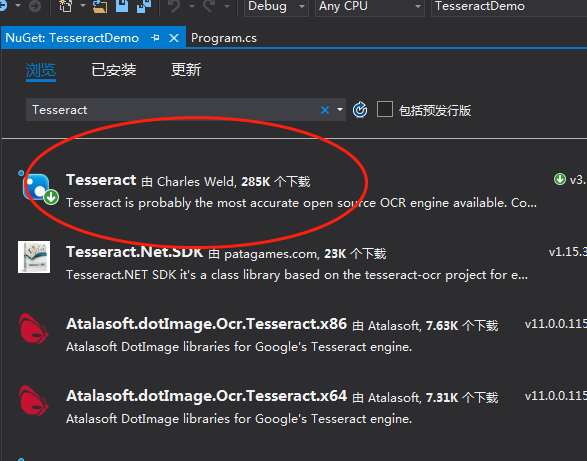
2.引用Tesseract-ocr库
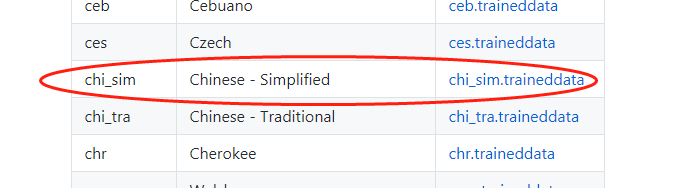
3.下载语言文件
下载地址 https://github.com/tesseract-ocr/tesseract/wiki/Data-Files#data-files-for-version-302
目前下载中文做实验
4.代码部分
static void Main(string[] args)
{
var img = new Bitmap(@”F:\1557288016(1).png”); //需要识别的图片
//F:\test\ConsoleApp1\TesseractDemo\tessdata 为语言包存放路径
var ocr = new TesseractEngine(@”F:\test\ConsoleApp1\TesseractDemo\tessdata”, “chi_sim”, EngineMode.Default); //使用chi_sim中文语言包做测试
var page = ocr.Process(img);
Console.Write(page.GetText());
Console.ReadKey();
}
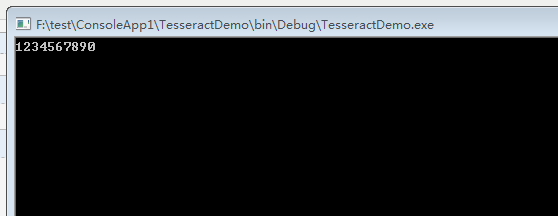
5.运行结果
图片:
识别结果:
6.在原图没任何处理 字库没训练下的结果识别率还不是很理想.
二. 使用 jTessBoxEditor 进行简单数训练
1.安装 jTessBoxEditor
下载jTessBoxEditor,地址https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
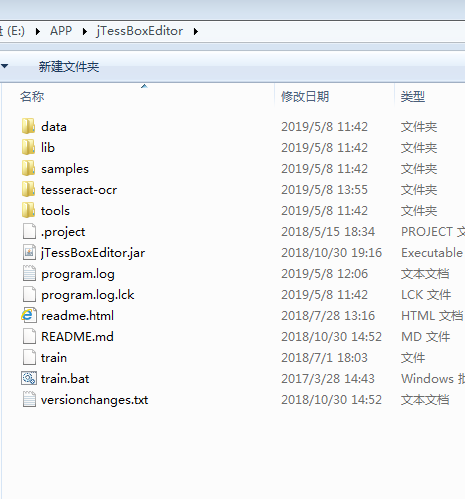
解压后得到jTessBoxEditor
2.由于这是由Java开发的,所以要先安装JRE 这里不阐述
3.准备样本图片 两个不同字体的字母
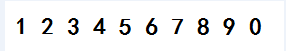
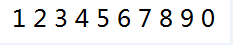
4.将图片转换成tif\tiff格式 可百度在线图片转换tiff**
**
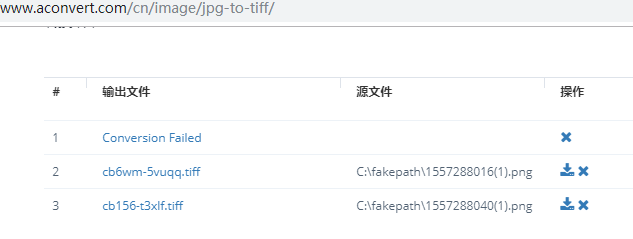
5.合并tiff样本图片
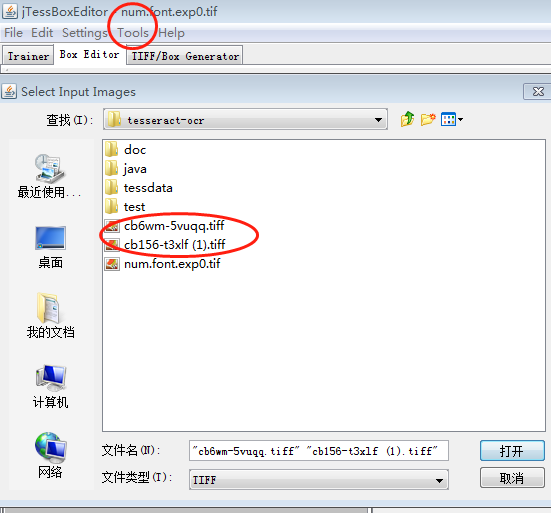
刚解压的目录找到一个【train.bat】打开 jTessBoxEditor >【Tools】>【Merge TIFF】 打开对话框选择两个tiff样本图片
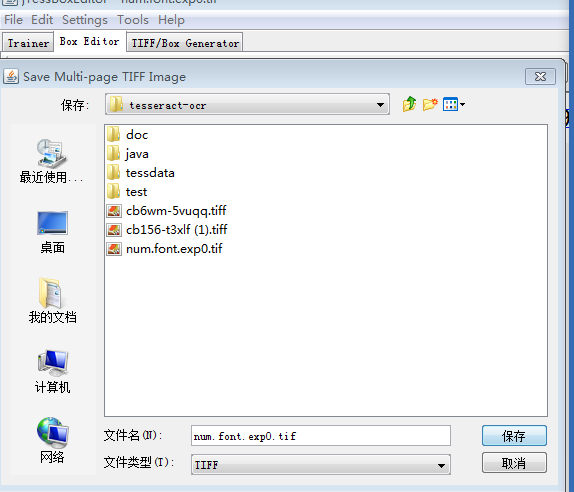
点击打开弹出保存合并后图片路径选择 这里我们命名为num.font.exp0.tif
6.生成BOX文件
由于没有设置环境变量暂时把所有样本图片放到jTessBoxEditor\tesseract-ocr 方便cmd命令
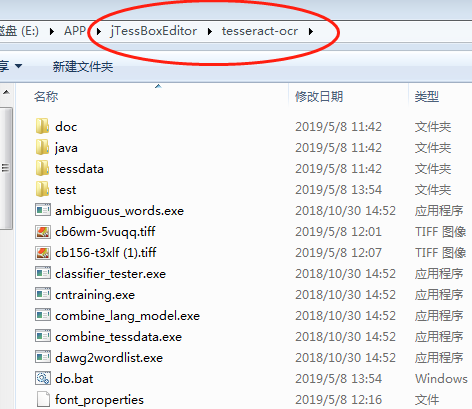
cmd定位到样本图片位置执行 命令:tesseract num.font.exp0.tif num.font.exp0 batch.nochop makebox 出现下面说明成功

语法说明
【语法】:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
【语法】:lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式
7.定义字符配置文件
还在在jTessBoxEditor\tesseract-ocr文件夹内,新建一个文本文件,名为font_properties,删掉.txt,用记事本打开,写入内容为:
font 0 0 0 0 0
语法说明
【语法】:
【语法】:fontname为字体名称,italic为斜体,bold为黑体字,
fixed为默认字体,serif为衬线字体,fraktur德文黑字体,
1和0代表有和无,精细区分时可使用
8.字符矫正
打开 jTessBoxEditor>【BOX Editor】> 【Open】,打开num.font.exp0.tif;矫正【Char】上的字符 每页没个样本字体蓝色框都要包含一个完整的字符一一对应
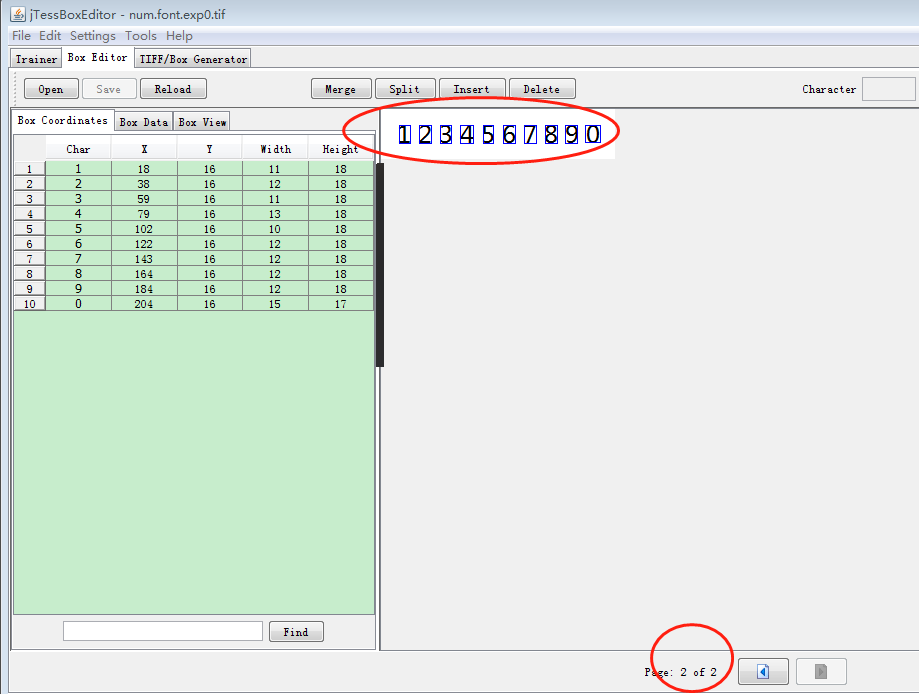
调整每页后保存
9.生成训练字包
还在在jTessBoxEditor\tesseract-ocr文件夹内,新建一个批处理文件do.bat (命名随意) 内容:**
**
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
然后cmd 执行do.bat文件
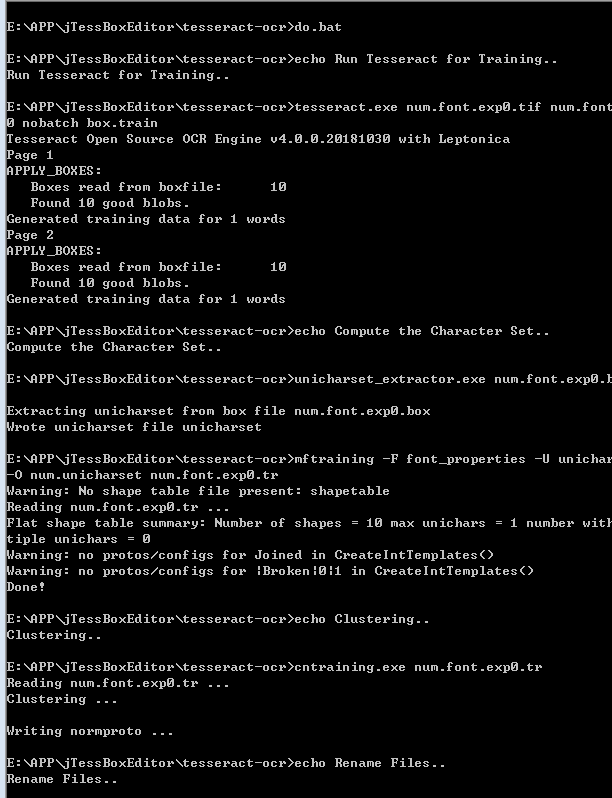
之后生成多个文件
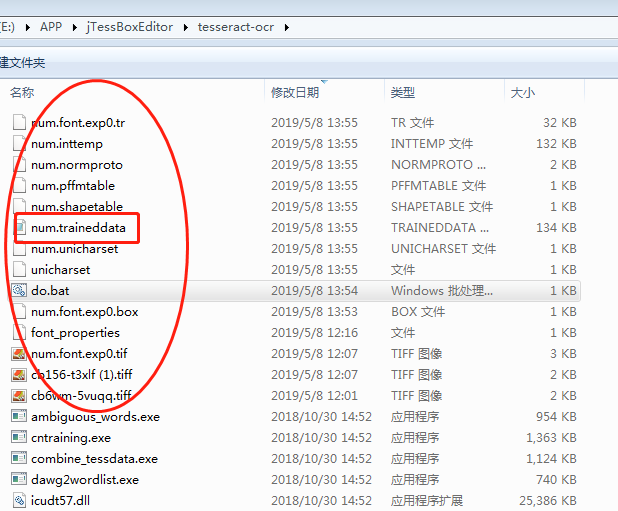
红色框框便是我们要的训练库
最后测试结果
var img = new Bitmap(@”F:\1557288016(1).png”);
var ocr = new TesseractEngine(@”F:\test\ConsoleApp1\TesseractDemo\tessdata”, “num”, EngineMode.Default);
var page = ocr.Process(img);
Console.Write(page.GetText());